17 Oct 2019
The longest halfweek in my recent memory is finally done, and I have lots of thoughts. First, the feeling of relief.
On Saturday, I gave a Python workshop, participated in a panel discussion with people 100x smarter than me, and judged some really great projects by the students participating in HackNEHS. It was an incredible and inspiring experience - one of Affectiva’s high school interns was one of the organizers, and he and his fellow organizers did a brilliant job. Seeing the proud parents rush up to take pictures of their children receiving their prizes was heartwarming.
On Sunday, my wife and I had the pleasure of showing my coworkers visiting from Cairo, Egypt Salem in October. We did corny haunted houses, shared a dinner, and wandered around downtown just being tourists. It was a great time to bond with people I had only seen over Zoom conference calls previously, but work with every day.
Tuesday was like Affectiva’s major holiday - the Emotion AI Summit. The entire company spent a ton of time and effort well into the night to set up our demos, prepare the space, and make sure the event went off without a hitch. Months ago, our CEO and cofounder, Rana, invited me to talk about the things my team was building to accelerate our AI development process, so Tuesday was the moment of truth. I got to the conference early in the morning to work the registration desk, and later in the afternoon gave my talk. I got a lot of great questions, got to watch people taking notes on what I was describing, but my favorite thing was seeing my entire team file in to listen to the talk and lend their support. It was an incredible experience. After the stress and hard work of that day, we had one hell of a team afterparty with very well-deserved letting loose.
I do have some learnings from this experience. My main takeaway has been to always look to serve others. I wouldn’t have been able to participate in HackNEHS if I hadn’t formed great relationships with our interns and been willing to help them when they needed speakers to accentuate their already impressive event. I wouldn’t be on the team I’m on at Affectiva if service wasn’t a major motivator - we build things only our coworkers see and use to make their lives better. The other was to always get out of your comfort zone. Public speaking is terrifying, whether I’m teaching high school students about Python or talking to AI professionals about the nitty-gritty of building an organization-wide platform. Both experiences were not just concentrated career growth, but a rare opportunity to meet smart, interesting people, give back to others, and show off some work that I’ve been proud of.
These last few days have been intense, stressful, and ultimately incredibly rewarding. And I can’t wait to put myself through the ringer again next year.

19 Feb 2018
A Brief Introduction
Version control systems (VCS) have a long history in software development. Superceding the previous major VCS, SVN, Git was created by Linus Torvalds in 2005 and has since exploded in popularity for its power and flexibility. One of the big drivers of this popularity is Github, an online hosting service for projects using Git as a VCS.
Things You’ll Need
- A terminal. GUI Git clients almost always cause more problems than they solve.
- Git installed locally.
Forking Up Your Code
Git is an essential tool for the modern developer, but in my experience, a lot of people struggle with the various ways it can be used. There are a number of workflows with Git, however one I’ve favored - especially with larger teams - is the fork and pull model. In this workflow, you have the main repo (the source), which is the one source of truth for the code and what gets deployed to production. You then fork the repo so you have a personal copy of it to work on. A key to this model is that you keep the master branch of your fork in sync with that of the source repository. Now you will clone down both the source repo and your fork: git clone <address to source repo>, navigate to the directory, and now add your fork as a remote: git remote add <remote name> <fork address>. Once this is done, you can verify that the remotes were set up correctly with git remote -v and you will see something like this:
origin git@github.com:source/source-repo.git (fetch)
origin git@github.com:source/source-repo.git (push)
forkremote git@github.com:<youraccount>/fork-repo.git (fetch)
forkremote git@github.com:<youraccount>/fork-repo.git (push)
The code bases will now look something like this:
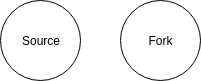
Branching Out
Now, when you want to make some changes, you will work on what is called a feature branch. This will allow you to have a source of truth (the master branch) locally, as well as a ‘separate’ codebase on which to do your work. This branch should only encapsulate the smallest unit of work that makes sense on your project, as well as any testing necessary.
Before making your new branch, ensure that your local master branch is up to date with the origin remote’s master branch. To do this, verify that you’re on your local master branch: git branch -a will show all local and remote branches with an asterisk next to the currently checked out branch:
* master
remotes/origin/HEAD -> origin/master
remotes/origin/master
To get back on master, check it out: git checkout master. Now you will want to pull down any changes, if your local repo is set to track the origin remote, git pull will suffice. Otherwise, explicitly pull by providing the remote and branch name: git pull origin master.
Now that you’re synced, you can create your branch with git checkout -b new_branch_name. You are now working on your new branch. All code will be confined here, and you can easily switch back to master or any other branches with git checkout branch_name, as long as any changes are committed.
Here’s a diagram of what your repos should look like:
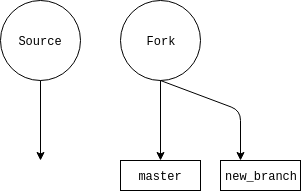
Steps only
- Sync to the
origin remote
a. git checkout master
b. git pull/git pull origin master
git checkout -b new_branch_name- Work
Making your PR
When you have tested and are satisfied with your work, you will be ready to submit this code to a repo’s maintainers - this will be made to the origin repo. First, though, we need to make sure our work is saved. You want to add the files, and there are a few ways to do this. git add . OR git add -A will update all file modifications in a directory and its subdirectories so that your git indexes will match the state of the directory (this is for git 2.x only, behavior is slightly different in git 1.x - see discussion here). You can also add individual files with git add filename.py or groups of files with fileglobs: git add *.py.
You will then need to commit these changes along with a descriptive commit message: git commit -m "your message here". You can add multiple commits to a PR if that makes sense given the culture of the project or team you’re working on.
After that, assuming you don’t need to rebase (more on that below), you will push to your own fork repo: git push fork new_branch_name. You can then go to the original repo in Github and you will be greeted with a small dialog inviting you to make a pull request. Click the button, and give your PR a descriptive but short title and a more verbose description. Now make the PR and get reviews.
If your PR gets added, it will look like this, with your commits in your PR a part of the main codebase’s history.
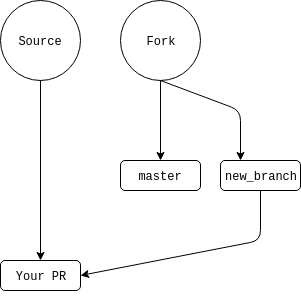
Change is Hard
Often, reviewers will request changes. It is totally okay to add more commits to reflect these changes - I usually like to do one commit per request or atomic change. Simply make sure you are still on your feature branch locally, make your changes, add with your favorite add mechanism (e.g. git add .), then commit the changes with git commit -m "message here" - this will give you a single commit. You can either push right away (pushes to your repo will be reflected in the PR), or add multiple commits and then push them with git push fork feature_branch - the procedure stays the same.
Let’s add a few commits to our diagram:
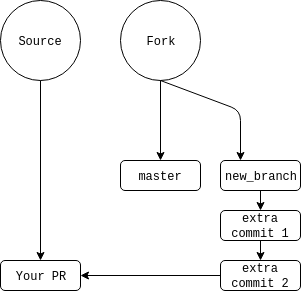
All Your Rebase Are Belong To Us
Outside Changes
What happens if, in the course of your changes, the maintainers of the repository merge in other change, desyncing your master (and therefore feature) branches? The repos now look like this:
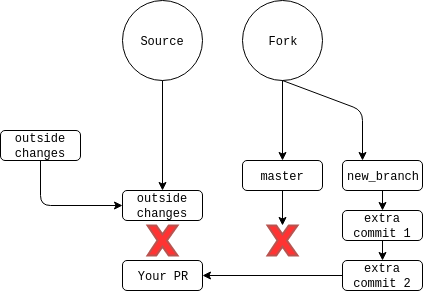
You will want to pull the changes and make that the new base on which you build your changes - this is called rebasing. When done, the new outside changes will be on the bottom of the stack of commits, with yours following. There is a single command that does this for you - git pull --rebase origin/master if wanting to PR to the origin remote and master branch. Some people advocate a simple git pull but that will pollute your PR and, eventually, the main repo history with extraneous merge commits. If it works, since you’ve changed the commit history: git push --force fork feature_branch.
Many times, though, you will see conflicts. These are areas in which both the original changes and your own affect the same parts of a file. When this happens, a three-way merge editor will launch. A what?
A Short Detour…
A three-way merge editor is an editor that will show you 3 versions of the code - your local branch, the code on the remote, and the code that you’ll eventually push. You can decide which lines will be included and which won’t. There are a lot of great tools to use, for Linux I’m partial to Meld. Other valid tools can be found by running git mergetool --tool-help. Once you have installed one, configure git to use it with git mergetool --tool=<tool>.
Back to Rebasing, Back to Reality
I slightly lied before. Your merge tool won’t automatically launch, git will report a conflict, and you will have to run git mergetool, which will launch your tool. Once you’ve made your changes to where all 3 files are equal, save and close your editor. Then you will run git rebase --continue. You may have further conflicts (especially if you have more than one commit on the feature branch), or you may not. If you do, repeat the steps above. Once there are no longer conflicts, push back to your feature branch with git push --force fork feature_branch.
Now the history will look something like this:
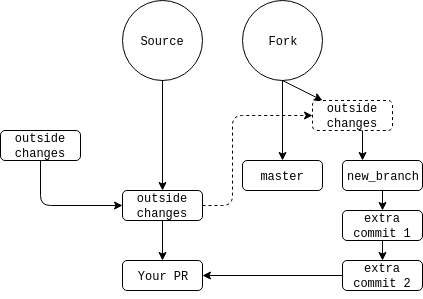
And your PR will now be good to go. Hopefully.
Rebasing to a Single Commit
If you have multiple commits, the maintainers may want you to rebase to a single commit, or fewer commits than you currently have. This is a little bit easier than merging in conflicts. Say you have 3 commits, as shown in our diagrams up to now. The final two commits should technically be part of your first commit in this scenario, so the maintainers asked you to rebase to a single commit. To do this, we will do an interactive rebase with the following command: git rebase -i HEAD~3 - this means we will interactively rebase from HEAD (which is a pointer to a commit, in this case the initial commit of the branch - read more here) to the 3rd commit. When you do this, an editor (often Vim or nanom but you can set this to another if you wish) will come up with the commit names and hashes:
pick e13b717 new_branch_commit
pick 2f7bf3f new commit 1
pick 8105378 new commit 2
# Rebase cb6f2cc..8105378 onto cb6f2cc (3 command(s))
I cut off some comments, but they expand on some of the commands we can use. These are pretty self-explanatory, so I won’t go into any but fixup, which is what we will be using. You will replace the bottom two picks with fixup or just f:
pick e13b717 new_branch_commit
f 2f7bf3f new commit 1
f 8105378 new commit 2
# Rebase cb6f2cc..8105378 onto cb6f2cc (3 command(s))
What pick does is tell git that we will be keeping that commit. fixup is a command that will fold the commit into the previous one and remove the commit’s log message. When done, you will save the file and close the editor, then push the code: git push --force fork feature_branch. Now our diagram looks like this:
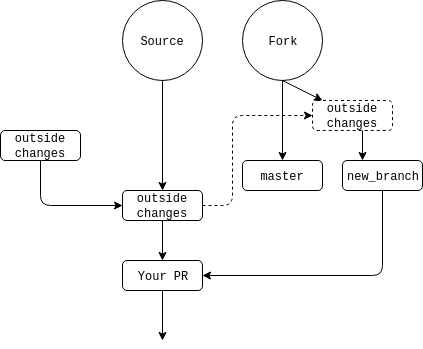
04 Feb 2018
The dust has settled. The boxes are (mostly) unpacked. The cats have claimed their perches. At the beginning of January, Tallahassee got its first real snow in decades, and my wife and I prepared to take our adventure to our mutual dream city, Boston. While the 1,300 mile trip could consume a post or two on its own, today I’d like to talk about what brought me from Tallahassee to Boston, and how I got there.
Like everything in life, there was an element of luck involved. I was lucky to have a great recruiter, working for me, I was lucky to have interviewed with people who saw the value in my projects in particular, as well as side projects in general, and saw a fit for me in a fast-moving team working on highly experimental data tooling. However, the harder your work, the luckier you seem to get - and there are elements from this experience that I think can aid people in any job search.
The Beginning of the Job Search
What motivated me to look in the first place? I enjoyed the team I worked with (the building we were in? Not so much), and while we never saw Tallahassee as our forever home, my wife and I both made great lifelong friends there and had a great routine. Well, as we were preparing for our first anniversary trip, a recruiter for Amazon reached out to me on LinkedIn. I wasn’t planning on taking it, but after the results of my pitching Danqex (formerly NASDANQ - and fodder for another post) and with the encouragement of my career sherpa (who also works for Amazon), I decided to go for it. That got me itching to see what was out there given my interests and experience - and there was a lot. I figured I’d look for remote opportunities, save up some money, then move in the early summer or fall to Boston. The best laid plans, yadda yadda yadda.
Updating My Resume
To prepare for this, I had to update my resume. I added some projects and experience I got while working at Homes.com, but I think the most important thing was adding my work as Danqex cofounder, CEO, and data lead. This was something I worried about - I didn’t want to give the impression that I’d up and leave right away for Danqex, but at the same time it was (and continues to be) a source of super-concentrated experience in a number of areas - team management, project management, development, technology selection, even dealing with investors and knowing a bit about how funding works. So I added it to my resume - one thing I’ve learned in my career is to be completely upfront in the job search, because the hunt is a lot like dating: a good fit is far more important than the quickest almost-fit. Danqex also worked as a great conversation starter - who doesn’t like to talk memes?
Mismatches and Encouragement
The Amazon interview came and went. My wife and I had just gotten back from our trip, and I hadn’t much time to review data structures and algos. I wasn’t aware that I’d have a coding test (something that is always a source of anxiety) at the first phone interview, so that happened and I powered through that anxiety because I had no choice. Getting that out of the way was great, and I actually enjoyed the problem given - unfortunately Amazon decided to pass on me. It was disappointing, but now I didn’t have to move to Seattle.
I had quite a few other interviews, which was actually very encouraging because my previous job searches did not often get past the resume submission. These were often great, geeking out with someone else about technologies we loved and work that we’d do. Unfortunately a lot of these were not good matches - often because of a lack of experience with their technologies. The types of companies that don’t encourage on-the-job learning (or can’t) aren’t the ones I necessarily want to work for - picking up a language to do work is pretty quick, even though mastering it takes many hours of work. Picking up supporting technologies (think Kafka, etc.) is much quicker.
One job I applied to I didn’t realize was for in Boston and was through an external recruitment firm. I was nervous when this became clear, because I’ve only heard bad things about these, but I am incredibly grateful for the experience and it worked out perfectly. The business model here is interesting: companies that don’t necessarily have the resources to do their own recruitment on a large scale will pay another firm to do it, in this industry this is mostly startups or companies undergoing very rapid growth. The firm that posted the ad I applied to was WinterWyman, and they have teams dedicated to different fields. The recruiter, Jamie, contacted me, and said he didn’t think what I applied to would be the ideal fit, but he’d talk to them anyway - in the meantime, though, he wanted to know what my priorities were as far as my career and what things are important for me in a company. I told him I was ready to make an impact on society in some way - one of the jobs I applied for was for a company doing research on various mental issues as detected in social media postings. I wanted to be able to take point on my projects and have ownership, have the opportunity to advance, work with interesting technologies, process lots of data, and a few others, but my most important priority was impactful work. He returned to me a list of companies that I did some research on, and picked a few. One didn’t want me because I didn’t have a CS degree (their loss - and I’m happy not to work in a culture with those attitudes), a few others dropped off, but one in particular was right up my alley and was really interested in me.
The Match
This company was PatientsLikeMe which has a track record of not only improving lives of patients through connecting them in support networks, but was also doing some groundbreaking research with the data that users of the platform provide. Impactful? You bet. They wanted a data engineer for a new data engineering team that supports the research team and builds tools to trial before bringing them to full production status. Ownership? Plenty. I had two phone interviews, one with my future boss, and one with a teammate. Both were a lot of fun, talking about Danqex/Nasdanq, my experience, my educational background, and more. Jamie helped me prepare for both, and called me quickly to let me know that the team was really excited about me and would be setting me up for a trip to Cambridge for an in-person interview.
I flew in to Logan (almost missed my flight because my car greeted us in the morning with a flat), spent a few days with my dad, and then got settled in my hotel in Cambridge. My recruiter had been giving me a lot of details on what to expect for the interview, which helped put me at ease, and after a good night of sleep I got dressed and headed over to the PLM offices. While there I went through a few rounds of interviewing, two with my future boss, one with the other team members, one with HR, and one with one of the scientists on the biocomputing team, who we’d be supporting. The topics ranged from the function of outer hair cells (the subject of my research in grad school) to the design of database tables given some features to RaspberryPis to how to trade memes for profit. Instead of an interview, it was more like meeting with a bunch of interesting and smart people that geek out over the same things I do, and getting to chat about our passions. It was fun.
After the interview I met with some family and before leaving, I got to meet Jamie in person for breakfast. He informed me there was another person being interviewed, but that I’d hear something within the next couple of weeks. A little over one long week later, Jamie called me to let me know an offer was coming. The offer came, and it was exactly what I was looking for and the match was officially made.
One mild issue - the job was not remote. We’d be moving to Boston on the heels of record-breaking cold with plenty of winter left for us.
Lessons learned
Wrapped up in all that are a few lessons that can be gleaned from this, I think:
- Work on your side projects, take them farther than makes sense, and be a cheerleader for them and the work you did on them.
- Be prepared to answer truthfully any hard questions about those projects. One of the questions asked was how my priorities would shift with this job in relation to Danqex. Of course, the job would come first, Danqex was born as a side project and that’s how we’re equipped to work on it. You’ll likely get those questions and more about your projects, and you should know them inside and out. Pitching to investors, while not feasible for many, was a great preparation for this.
- Get outside of your comfort zone with technologies you work with. This is especially useful if you, like I was, work with a less in-demand language at your current job.
- Find the best match, not the the first yes. I’ve been working at PLM now for just under 3 weeks, and it has been the best match for me. A fun, stimulating culture (we have journal club between 1 and 3 times a week, and also a well-stocked beer fridge!), brilliant people to work with (2 of my teammates have PhDs from MIT, the other studied at WPI), a team that’s all about rapid prototyping, proving a tool we make, and then letting it mature to another team to maintain, and a shared drive to truly push the science of chronic illness and improve the lives of our patients in tangible ways. Work that truly matters is one of the greatest motivators of all.
- To help with the above lesson - don’t wait (if you can help it) until you absolutely need a job to start looking for your next step. This keeps you from making any spur of the moment emotional decisions, and keeps the ball in your court as you wade through rejections and negotiations.
29 Oct 2017
Recently at Homes.com, one of my coworkers was charged with speeding up a batch process that we were required to run at a scheduled interval. No big deal, but he was stuck: the process required a number of steps at every typical ‘stage’, for identifying the data we needed to pull, for pulling the data, for transforming the data, and for writing the transformed data back to Mongo. When he was talking about the process, I realized this would be a perfect use case for Mongo’s aggregation framework. I offered to help, based on my experience with the aggregation framework I got while working on NASDANQ, and immediately got to work on designing an aggregation pipeline to handle this process.
Original Solution
This batch process exists to update mean and median home value data for a given area. A rough overview is laid out below:
- Query a large collection (> 1 TB) for two fields that help identify an area in which a property resides.
- Join into a single ID
- Use this to pull location data from another collection on a separate database (> 25 GB).
- For each property in this area, we pull from another collection the price.
- These are loaded into an array in our script, and then we iterate to find the mean and median.
At our estimates, if we could run this process to completion with no interruption, it would take ~104 days to finish. This is unacceptable for obvious reasons.
Attempt the First
We ran into an architecture issue early on. MongoDB’s aggregation pipeline doesn’t support working across multiple databases, and the collections we needed to work on were split between a few databases. Luckily, we were able to move the collections onto a single database so we could start testing the pipeline. We started with a 9 stage monster - the multiple collections we had to match on required multiple match stages and a stage to perform what was essentially a join. Because the data is stored in memory at each stage, and each stage is limited to 100MB of memory we first attempted to switch on the allowDiskUse option to allow the pipeline to at least run. And run it did. Our DBA team notified us that we were spiking memory usage to unacceptable levels while the pipeline was running.
We reduced the pipeline to 7 stages - we take location data as inputs to the pipeline, match on this to the 25GB collection, use $lookup to join in the 1TB collection holding the ID fields on one of the ID fields, project the fields we actually want, unwind, redact, sort by value, group by location (2 fields), take an average, and sort again. The pipeline looked like this:
$match->$lookup->$project->$unwind->$redact
|
V
VALUES<-$sort<-$avg<-$group<-$sort
This failed at $lookup. Why? For many locations, we were joining in nearly 1 million documents per month of data, and we wanted multiple years of that data. Across all locations, this fails to solve our performance issues. It also fails to run.
Attempt the Second
Our first thought was to add the unique identifier (which was a combination of two fields in different collections) to the 1TB collection, but that was not workable due to the size of the collection. Instead, what we can do is project a concatenated version of the two fields we are using as a UID, use $lookup to join in the 25GB collection on that - because it’s much faster to make this change to the smaller collection. Simultaneously, we were testing performance differences in sorting in our ETL code vs. within the pipeline itself. Since the time taken in the code to run these sorts was trivial, we could remove these stages from the pipeline. Now we are looking at all IDs for a single month taking 10 days, but we need to run multiple years - this comes out to worse performance than the original solution.
However, an interesting finding was when we ran a single identifier at a time - 1 for one month took about a minute. But one location identifier over 3 years only took 10 minutes. I mention this because it demonstrates how nicely aggregation pipeline performance scales as your dataset grows. And remember how I said we projected all IDs for one month taking 10 days? In light of the results showing that time taken in the pipeline does not scale linearly with data size, we ran the pipeline and found that a single month for all identifiers took about 14 hours. This is a big improvement, but not enough. So we look for more optimizations.
Attempt the Third
This was a smaller change, and on its own created a big change in time taken to process our data. We re-architected our data so that we had a temporary collection of a single month of data. We generally process one month at a time, despite the overall length of time we want. We were able to cut the time in half from the previous attempt - a single month for all identifiers now took only 7 hours and we were now not querying the full 1TB collection when we only wanted a small piece of it anyways. Creating the temporary collections is trivial and done by our counterparts on the DBA team as a part of their data loading procedures.
Attempt the Fourth
After seeing these results, management was fully convinced of the need of redesigning how we stored this data. Let this be a lesson: hard data is very convincing. So now each month’s data will be in its own collection, when we load data the location data will also be added in to these monthly collections avoiding costly joins via $lookup. Surprisingly, while testing, adding this information did not impact our overall data preloading times. This location data was also indexed for quicker querying. All of this allowed us to go from a 7-stage aggregation pipeline to 3. Now we start with the split collections, project the fields we are interested (location, value, etc.), group on location, average them and also add all individual values to an array (for sorting and finding the median in code), and output to a temp collection. If we want to process a period of time longer than a month, we rinse and repeat.
For all identifiers in each month, our processing time went from 7 hours to 8 minutes. Then the queries made on the generated collections to get the computed averages plus arrays of individual values to calculate the median in code added a minute per output collection if we did it serially. Being primarily ETL pipeline builders, we do nothing serially. We tested with 7 workers, and the added processing time goes from a minute to 30 seconds. In production, we have a worker pool that numbers in the hundreds, so this additional time was satisfactory. If we assume a conservative 7.5 minutes to process a month of data, then projecting to 3 years we estimated we should see runtime of around 4.5 hours. We decided we were happy with this, especially when we considered the original process was projected to take 104 days.
Conclusion
I learned a lot of lessons from this little project, and wanted to distill them here as a sort of tl;dr to ensure that they can be passed on to the reader.
- Management is convinced by data. Run your proposed changes, show them graphs or numbers of performance improvements. You’re all working to the same goal.
- ABB. Always Be Building. In my case, my work on NASDANQ gave me the knowledge I needed to hear a teammate’s struggles, identify a use case, and implement a plan to alleviate those issues.
- Standups suck, but they’re useful. Hearing my teammate’s struggles with this code during a standup meeting allowed me to assist him and come up with a workable solution.
- More generally, communication is important. Not only was understanding my teammate’s needs important, but this project required constant contact between our DBA team, me and my teammate (who was running many of our tests), and management of our team, the DBA team, and the larger team we report to.
- And, finally, MongoDB’s aggregation pipelines are incredibly powerful. They’re worth learning and getting familiar with if you work with sizable datasets at all.
16 Jun 2017
Note: This was first written in response to this excellent discussion on dev.to. I strongly recommend reading through the whole discussion, whether you feel like you’re suffering from imposter syndrome or not, there is some great advice and experience shared there.
I started in this industry after being a hobbyist and having no formal CS background - I studied neuroscience and was well on my way to an academic career when I decided (with the assistance of a friend who from then on became my career sherpa) I should take my hobby into a fulltime job. I was speedily doing code challenges, TA’ing classes, running my thesis experiments, and writing my thesis while simultaneously applying to every job I could find.
After over 100 submissions with either rejections or no responses, I finally had an interview! Some time after, I was plopped into my first software job in a new city, and had no idea what I was doing. I struggled with imposter syndrome for almost a year - how did I conquer this? Sometimes it’s hard to really think about, and sometimes I wonder if I truly did ever conquer it. A few different things, in my mind, helped me with this:
-
Realizing this is a very meritocratic industry, despite how HR departments treat things. This becomes most clear when other developers start coming to you with questions, and you can comfortably answer them. This comes with the next point:
-
PRACTICE. I always felt like (and still do) that I have to prove something because I don’t have a degree. I do a lot of coding and reading about coding in my free time - it helps that it’s a passion of mine, but I make sure to maintain balance with other things in my life, such as exercise, pleasure reading, etc. But this gets you the knowledge to start answering questions your teammates you have, and as you do this more and more often (it’ll come as you practice, because the questions will naturally seem like easy ones to you), your own confidence will build along with the confidence others have in you. It’s a nice positive feedback loop.
-
Work on actual projects for your practice - yes you should take online courses, yes you should do coding practice, but you should contribute to open source, build projects that are interesting to you, etc. This skill transfers over - and I actually have a story about an instance in which this happened to me just over the last week, but it’s a long one that should probably be its own post.
-
Jump into the deep end. This is always a leap of faith - once you get past the drowning feeling, you’ll find yourself swimming. Challenge yourself - take the initiative to rewrite your company’s testing procedures, learn big data processing by building a big data app, deploy your first single page app, do some embedded programming - then break it all or have others break it, and fix it. And break it. And fix it. It will then become routine and old hat - then comes the knowledge, the confidence, and it starts replacing that feeling of being an imposter.
I think the key takeaway here is building confidence, and constantly pushing your limits. Failure doesn’t exist - you will always learn something and become better, and as you build that understanding and the confidence I talked about above, you’ll welcome ‘failure’ and success: failure is learning, success is demonstrating what you learned.
As for my personal example - I’ve been in the industry for 3 years now, am building out my own startup (remember when I said to jump into the deep end?), and am loving every minute of it.
